再帰的ネットワークRNN
RNN
RNNは時系列データ処理に適したNNで、1時刻前のリカレント層の状態を、次の時刻のリカレント層へ伝播する.
特徴:勾配消失や爆発を防ぐため、勾配クリッピングを行う.閾値より大きい時、勾配のノルムを閾値に正規化するため、勾配×(閾値/勾配のノルム)と計算する.
RNNの課題:入力された情報の影響が長期的に及ぶ場合と短期にしか及ばない場合を区別できない (LSTM).<順伝播の式>
# RNNレイヤの実装 class RNN: # 初期化メソッドの定義 def __init__(self, Wx, Wh, b): self.params = [Wx, Wh, b] # パラメータ self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] # 勾配 self.cache = None # 変数の保存用 # 順伝播メソッドの定義 def forward(self, x, h_prev): # パラメータを取得 Wx, Wh, b = self.params # 順伝播を計算:式(5.10) t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b # 重み付き和 h_next = np.tanh(t) # 活性化 # 逆伝播に用いる変数を保存 self.cache = (x, h_prev, h_next) #隠れ層の状態の保存、隠れ層の出力を次時刻の入力に使用するため return h_next # 逆伝播メソッドの定義 def backward(self, dh_next): # 変数を取得 Wx, Wh, b = self.params # パラメータ x, h_prev, h_next = self.cache # データ # 勾配を計算 dt = dh_next * (1 - h_next ** 2) db = np.sum(dt, axis=0) dWh = np.dot(h_prev.T, dt) dh_prev = np.dot(dt, Wh.T) dWx = np.dot(x.T, dt) dx = np.dot(dt, Wx.T) # 結果を格納 self.grads[0][...] = dWx self.grads[1][...] = dWh self.grads[2][...] = db return dx, dh_prev
実装したクラスを確認する.
# インスタンスを作成 layer = RNN(Wx, Wh, b) # 順伝播の計算 h1 = layer.forward(x1, h0) print(h1.shape) # 逆伝播の計算 dx1, dh0 = layer.backward(dh1) print(dx1.shape) print(dh0.shape) for grad in layer.grads: print(grad.shape)
- BPTT(BackPropagation Through Time)で時間展開した上での誤差逆伝播と同じ、一階微分である.
- 全結合NNより、RNNは勾配消失や勾配爆発がおきやすい(系列長が長くなる).
- 勾配消失や勾配爆発の起きやすさは、活性化関数による変わる.
- 勾配爆発を防ぐため、ReLU関数よりも、Sigmoid関数やTanh関数が適している.→勾配消失の回避のため、勾配クリッピング

RNNでのSGDによって最適化を行う.最も単純に全時刻にわたって誤差逆伝搬を行うBPTTという手法がある.
サンプルコード
def bptt(xs, ys, W, U, V): hiddens, outputs = rnn_net(xs, W, U, V) dW = np.zeros_like(W) dU = np.zeros_like(U) dV = np.zeros_like(V) do = _calculate_do(outputs, ys) # batch_size, n_seq = ys.shape[:2] for t in reversed(range(n_seq)): dV += np.dot(do[:,t].T, hiddens[:,t]) / batch_size delta_t = do[:, t].dot(V) for bptt_step in reversed(range(t+1)): dW += np.dot(delta_t.T, xs[:, bptt_step]) / batch_size dU += np.dot(delta_t.T, hiddens[:, bptt_step-1]) / batch_size delta_t = delta_t.dot(U) # RNNでは中間層の出力h_tが過去の中間層出力 h_{t-1}...h_{1}に依存する. # RNNにおいて損失関数をWとUに関して偏微分するとき、それを考慮する必要あり、 dh_{t} / dh_{t-1} = Uである return dW,dU,dV
def rnn_net(xs, W, U, V): batch_size, n_seq = xs.shape[:2] hidden_size = W.shape[0] hiddens = np.zeros((batch_size, n_seq, hidden_size), dtype=xs.dtype) for t in xs.shape[1]: hiddens[:, t] = _activation(x[:, t].dot(W.T) + hiddens[:, t-1].dot(U.T)) #入力xから中間層への重みW、1ステップ前の中間層出力h_{t-1}から中間層h_{t}への重みU、それを合わせた中間層出力 outputs = _activations(hiddens.dot(V.T)) return hiddens, outputs
def clip_grads(grads, max_norm): total_norm = 0 for grad in grads: # Gradsは各パラメータの勾配をまとめたList total_norm += np.sum(grad ** 2) ## total_norm = np.sqrt(total_norm) # 勾配のL2ノルムを取った値をまとめている変数 rate = max_norm / (total_norm + 1e-6) if rate < 1: for grad in grads: grad *= rate
RNN派生モデル<エコーステートネットワーク>
入力の重みUと隠れ層の重みVをランダム値で固定し、出力の重みのみを学習する。勾配消失が発生しにくく、学習が速くなる.<リーキーユニット>
隠れ層に線形結合を導入して移動平均の効果を得る.
双方向 RNN
文章内の文字の穴埋めタスクや過去から現在だけでなく未来から現在までの系列情報を用いることが有効である.
中間層の出力を、未来への順伝播と過去への逆伝播の両方向に伝播する.
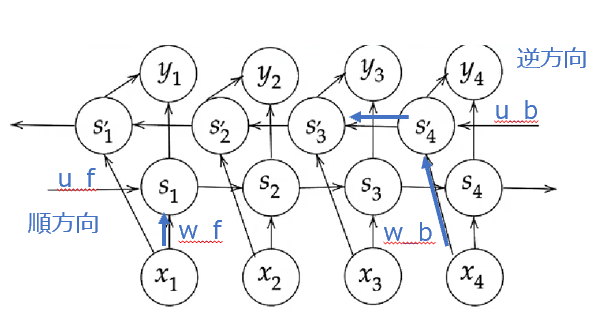
同じ場所に同じものを合体する.一つの特徴が得られる.
def bindirectional_rnn_net(xs, W_f, U_f, W_b, U_b, V): xs_f = np.zeros_like(xs) xs_b = np.zeros_like(xs) for i, x in enumrate(xs): xs_f[i] = x xs_b[i] = x[ : :-1] hs_f = _rnn(xs_f, W_f, U_f) hs_b = _rnn(xs_b, W_b, U_b) hs = [np.concatenatie([h_f], h_b[::-1]], axis=1)] for h_f, h_b in zip(hs_f, hs_b)] ## 順方向と逆方向に伝播した時の中間層表現を合わせたものが特徴量となる ys = hs.dot(V.T) return ys
RNN Encoder-Decoder と Seq2Seq
長期依存性の課題
ゲート付きRNN
LSTM
構成要素:CEC、入力ゲート、出力ゲート、覗き穴結合

入力ゲート
:今回の入力
:今回の重み
:前回の出力
:前回の重み
出力ゲート
:今回の入力
:今回の重み
:前回の出力
:前回の重み
忘却ゲート
:今回の入力
:今回の重み
:前回の出力
:前回の重み
入力と隠れ状態結合状態
セルの値
今回覚えておくべき割合と判断した情報
(tanhは恒等写像に置き換え、バイアス省略)
出力値
CEC:
中間層に記憶をため込む(記憶機能のみ).学習機能がない.
入力ゲート:CECの覚え方を身に付ける学習
出力ゲート:どんな感じでCECの情報を使うを学習
しかし、ずっと過去の情報が削除できないため、忘却ゲートを入れる
さらに、CEC自身の値は、ゲート制御に影響を与えないため、覗き穴結合を入れる.
記憶セルの状態を結合させる.
サンプルコード
def lstm(x, h_prev, c_prev, W_in, W, b): n, m = h_prev.shape A= np.dot(x, Wx) + np.dot(h_prev,Wn) +b #全部の行と変数mの値分の列を指定 f=A[ : , : m] g=A[ : , m: 2*m] i=A[ : , 2*m: 3*m] o=A[ : , 3*m: ] f = sigmoid(f) # forgetゲート g = np.tanh(g) # 新しい記憶ゲート i = sigmoid(i) #inputゲート o = sigmoid(o) # outputゲート c = f * c_prev+ g * i #次の時刻の記憶セル h = o * np.tanh(c) #次の時刻の隠れ層におけるoutput return h, c
GRU
Gated Recurrent Unit
LSTMはゲートが3つで計算負荷が高い課題がある.
パラメータを大幅に削減し、精度はLSTMと同等.
記憶ゲートがなく、リセットゲートと更新ゲートがある.

GRU (Gated Recurrent Unit) | CVMLエキスパートガイド
リセットゲート
更新ゲート
次、仮の隠れ状態
出力値
前回:
今回:
サンプルコード
def gru(x, h_prev, W_in, W): n,m = W_in.shape W_in_z, W_in_r, W_in = W_in[:, :n], W_in[:, :n],W_in[:, 2*n:] W_z, W_r, W = W[:, :n], W[:, n:2*n], W[:, 2*n:] z = _sigmoid(np.dot(x, W_in_z) + np.dot(h_prev, W_z)) # updataゲートの出力値 r = _sigmoid(np.dot(x, W_in_r) + np.dot(h_prev, W_r)) # resetゲートの出力値 h_hat = np.tanh(np.dot(x, W_in) + np.dot(r*h_prev, W)) #過去の隠れ状態とリセットゲートの出力のアダマール積 r * h_prev h= (1-z) * h_prev + z * h_hat #更新ゲートの出力を混合比とする過去の隠れ状態と仮の隠れ状態の混合が入る # or h_next = z*h_pre + (1-z) * h_hat return h
長期依存性の最適化
Attention
- Soft attention :
softmax関数で確率分布を求めてその確率分布を用いて重みつき平均を求める方法である.
- Hard attention:
softmax関数で確率分布を求めてその確率分布に従って抽出された1点だけを得る方法である.
1.Source target attention: keyとValueがエンコーダ側の情報、Queryがデコーダ側の情報で分ける。2つの系列間の対応関係をとらえる.
2. Self attention:同じ情報源から計算するもの、同じ文章内の単語間の関係をとらえる.
3. Global attention:Attentionを使わない系列変換モデルでは長系列データ学習は難しい、エンコーダの初期に入力された情報がデコーダまで伝わりづらい
「デコーダの対象時刻の隠れ層の出力」と「エンコーダの各時刻の隠れ層の出力」から重みベクトルを算出して、
その重みベクトルと掛け算して、Ctが得られる.<コード>
デコーダの隠れ状態のサイズ Nx H
h.reshape(N,1,H).repeat(T, axis=1)
アテンションの重みは N X Nとなる.
H方向に合計np.sum(t, axis=2)
深層学習_画像認識_応用
- AlexNet(2012年)
- GoogLeNet(2014年)
- VGG(2014年)
- YOLO(2016年)
- SSD(2016年)
- ResNet(2016年)
- R-CNN, Fast R-CNN, Faster R-CNN
- FCN(2015年)
- SegNet(2017年)
- UNet(2015年)
- MobileNet(2017年)
- DenseNet (2018年)
- FCOS(2019年) paper
AlexNet(2012年)
2012年のILSVRCの優勝モデル
GoogLeNet(2014年)
2014年のILSVRCの優勝モデル
フィルタサイズの異なる畳み込み層を並列に配置、それぞれの結果をチャンネル方向に結合して出力するInceptionを多層に積み重ねた構造を持つ.
Inception:
①フィルタの値を各画素値にかけ、すべて足し合わせたものが最終出力値となる.
②ネットワークの途中から補助的分類器と呼ばれるサブネットワークにおいても予測し、逆伝播で勾配消失を回避する.
③サイズの異なる畳み込みを並列に重ね、複数のスケールの特徴を抽出することができる.層を深くして複雑の特徴を表現できるようになる.
④Inceptionのバージョン:Inception-ResNetはResNetアーキを採用した;Inception-v3はBatch Normalizationを採用した;Inception-v2はInceptionモジュールで使用される畳み込みフィルタの大きさを変更した.
GAP(Global Average Pooling)の採用:最終の全結合層の代わりに取り入れた手法である。各チャンネルの値の平均を求めて、各チャンネルの平均値を要素とするベクトルに変換することで過学習を抑制する.全結合層ですべての画素値を使う場合より大幅に計算量を削減できる.
VGG(2014年)
2014年のILSVRCの準優勝モデル
特徴:AlexNetより深い層で、小さな 3×3フィルタ(全部3x3に統一)中心の構造にして、プーリングを行う.畳み込み層と全結合層を連結したシンプル構造である.
問題点:層が深くなったことで勾配消失問題
YOLO(2016年)
YOLOシリーズの著者とリンク集(2023/01のv8まで) - Qiita
特徴:入力画像を複数の小領域に分割し、各小領域ごとにクラス分類とbboxの位置や大きさの回帰を行う
SSD(2016年)
特徴:大きさの異なる複数の特徴マップを使って、クラス分類やbbox回帰を行う
ResNet(2016年)
ResNet
F(x)は、入出力の差分 H(x)-xを学習
R-CNN, Fast R-CNN, Faster R-CNN
R-CNN (2014年)
特徴
①選択的探索(Selective Search)を使って物体が存在する候補領域を求めて、その領域を切り抜き、畳み込み層による特徴抽出を行う.
②NMS(Non Maximum Supression)を使って、IoUと呼ばれる評価指標を基準に画像を認識する.
SVMによるクラス分類と全結合層のbbox座標の回帰を行う.
CNNのインプットに合うように候補領域の画像をリサイズする.
課題
課題1:候補領域ごとに畳み込みによる特徴抽出が必要となる (→Fast R-CNNでは)
課題2:選択的探索による候補領域すべての決定にCNNの順伝播計算で検出時間がかかる (→Faster R-CNNでは)
Fast R-CNN(2015年)
2015年のILSVRCの優勝モデル、初めて人間のエラー率 5% を上回る精度を達成した.バッチ正則化を導入した.
R-CNNの課題1に対して、画像全体を複数解畳み込んで特徴マップを生成し、選んだ特徴マップから各候補領域に該当する部分を抜き出す.
物体候補領域の大きさにかかわらず固定サイズの特徴マップを抽出するROIプーリングを行う.
処理フロー:入力画像⇒CNNで特徴マップの作成+Selective Searchで候補領域の作成⇒候補領域に従って特徴マップを切り出す⇒固定サイズにプーリング⇒全結合層⇒Softmax関数でクラス分類
Faster R-CNN(2015年) paper
R-CNNの課題2に対して、領域提案ネットワーク(Region Proposal Network)というサブネットワークで候補領域を選ぶ.検出時間が短縮できた.
各スライディング・ウィンドウには、k個のアンカーボックスを設定する.
k個のアンカーボックスは、それぞれ異なるスケールとアスペクト比を持つ矩形領域である.
RPNへ入力される特徴マップの(H,W,C)の場合、HxW個のスライディング・ウィンドウごとにk個のアンカーボックスが存在するため、アンカーボックスの個数はHxWxkとなる.
RPNの訓練の時の損失関数の式:
i: バッチ内のアンカーボックスのインデックス.
pi: 番目アンカーボックスの物体らしさ(Objectness)確率の[1: 物体, 0: 背景]の正解値.
piハット: piの予測値.
ti: 番目アンカーボックスの修正量の真の座標ベクトル
tiハット: アンカーボックスの修正量の予測の座標ベクトル
は、回帰損失にかかる係数.正例(物体)のアンカーボックスの場合のみ回帰損失を加味するため
分かりやすい説明:
Faster R-CNNにおけるRPNの世界一分かりやすい解説. 今更ですがFaster… | by Kai | LSC PSD | Medium
Faster R-CNN: 2ステージ型の物体検出CNNの元祖 | CVMLエキスパートガイド
FCN(2015年)
特徴
①全結合層の代わりに畳み込み層を使用するため、入力画像サイズが異なっていても単一のモデルで予測できる
②大きさの違う複数の特徴マップを転置畳み込み(transposed conv)で拡大し、大きさを揃えた上で各画素ごとに足し合わせることで、物体の詳細な情報を捉えることができる.
SegNet(2017年)
エンコーダとデコーダにより構成された、自己符号化器型のCNNである.
UNet(2015年)
SegNet,FCNよりも高精度である.
MobileNet(2017年)
特徴
「depthwise convolution」と「pointwise convolution」の組み合わせで軽量化を実現している
- 通常の畳み込み層のパラメータθ数
- depthwise convolutionのパラメータθ数
- pointwise convolutionのパラメータθ数

計算コストは以下のパラメータの大きさに乗算的に依存していること
- 入力特徴マップのチャネル数
- カーネルサイズ f ×f
- 出力チャネル数
- 特徴マップサイズ DF × DF
通常の畳み込み層のパラメータθ数
depthwise convolutionのパラメータθ数
pointwise convolutionのパラメータθ数
MobileNet モデルは、これらの各項とその乗算的関係に対応することで計算コストを削減する.
具体的には、depthwise convolutions convolutionsを用いることで、出力チャネル数とカーネルサイズが乗算されることを解消する.
E資格合格に向けて 深層学習day4 (応用モデル) - Qiita
軽量モデルに新風を巻き起こした代表格!MobileNetV1 を詳細解説! | DeepSquare
Segmanticのように広い領域を参照する必要があるタスクの場合、単にフィルタサイズを大きくすると、パラメータ数が増加する.
そのため、少ないパラメータ数で広い領域を参照できる畳み込みはDilated convolutionである.
生成モデルのように小さな画像から大きな画像を生成する場合に使う畳み込みはtransposed convolutionである.
DenseNet (2018年)
- 特徴
①DenseBlock
DenseNetでは前にある全てのノードに対してスキップ接続を行う.
DenseNetのスキップ接続では、ResNetの入力と出力を加算するのではなく、連結するため、チャンネル数が変わる.
(一方、ResNetでは画像の要素同士を加算するため、チャンネル数は増えない)
②Transition Layer
Dense Blockの間にプーリング層を挿入して画像サイズを変更する.
FCOS(2019年) paper
Fully Convolutional One-Stage Object Detection
RetinaNet,SSD,YOLOV2,V3やFasterR-CNNでの問題点:
従って、アンカーボックスフリーが必要となる
one-stage:bboxの候補領域の選定とクラス判別を一括で行う→計算コスト小
center-ness 目的は物体中心に近い位置での誤差を大きくする
ラベルと予測されたCenter-nessを、Binary Cross Entropy関数(BCELoss)で計算
損失関数では、分類計算 LclsはFocal Loss損失関数;四次元ベクトル LregはIoU Loss損失関数
JDLA_全体リスト
機械学習
実用的な方法論
ハイパーパラメータの選択
- 手動でのハイパーパラメータ調整
- グリッドサーチ
- ランダムサーチ
- ベイズ最適化
- モデルに基づくハイパーパラメータの最適化
方法
- 主成分分析、K-NN、K-means
- サポートベクトルマシーン(SVM)
強化学習
①方策勾配法
②価値反復法
深層学習
順伝播型ネットワーク
- 全結合型ニューラルネットワーク
- 損失関数 最尤推定による条件付き分布の学習
- 活性化関数 "シグモイド関数 Softmax関数 ReLU, Leaky ReLUtanh"
- 誤差逆伝播法およびその他の微分アルゴリズム
深層モデルのための正則化
①パラメータノルムペナルティー
L2パラメータ正則化= Ridge正則化 L1正則化=Lasso正則化
②データ集合の拡張
Data Augmentation Random Flip・Erase・Crop・Contrast・Brightness・Rotate, MixUp
③ノイズに対する頑健性 主力目標へのノイズ注入
④マルチタスク学習
⑤早期終了
⑥スパース表現
⑦バギングやその他のアンサンブル手法
⑧ドロップアウト
深層モデルのための最適化
①学習と純粋な最適化の差異
②基本的なアルゴリズム 確率的勾配降下法 (SGD)モメンタム法
③パラメータの初期化戦略
④適応的な学習率を持つアルゴリズム (パラメータ更新の方法) NAG AdaGradRMsrop AdaDelta Adam
⑤最適化戦略とメタアルゴリズ バッチ正規化 Layer正規化 Instance正規化 教師あり事前学習
畳み込みネットワーク
①畳み込み処理
②プーリング
回帰結合型ニューラルネットワークと再帰的ネットワーク
①回帰結合型のニューラルネットワーク
②双方向 RNN
③Encoder-Decoder と Seq2Seq
④長期依存性の課題
⑤ゲート付きRNN LSTM GRU
⑥長期依存性の最適化 勾配のクリッピング
⑦Attention
生成モデル
①識別モデルと生成モデル
②オートエンコーダ(VAE 、VQ-VAE)
③GAN(DCGAN、 Conditionnal GAN)
深層強化学習
強化学習 - ディープランニング E資格
深層強化学習のモデル(AlphaGo A3C)
深層学習の適用方法
画像の局在化・検知・セグメンテーショ
FasterR-CNN YOLO SSD MaskRーCNN FCOS
音声処理
WaveNet サンプリング、短時間フーリエ変換、メル尺度 CTC
様々な深層学習
グラフニューラルネットワーク
グラフ畳み込み GCN
スタイル変換
pix2pix
距離学習 Metric Learning
①2サンプルによる比較 SiameseNet
②3サンプルによる比較 TripletLoss
メタ学習(Meta Learning)
初期値の獲得 MAML
深層学習の説明性
①判断根拠の可視化 Grad-CAM
②モデルの近似 LIME, SHAP
深層モデルのための最適化
目次
SGD
データ1つだけ をサンプルし、最急降下法にランダム性を入れる。
更新式
サンプルコード
param[key] -= self.lr * grad[key]
lr: 学習率
特徴(課題)
SGDの非効率な探索経路による。それは勾配の方向が本来の最小値ではない方向を指しているため。(それを解決するため、Momentum)
Momentum
パラメータθの更新式
サンプルコード
self.v[key] = self.momentum[key] * self.v[key] - self.lr * grads[key] param[key] += self.v[key]
lr: 学習率
特徴
大域的な最適解。学習率の値が重要である。小さすぎると学習時間が長い、大きいと発散する。大きく学習して、どんとん小さく学習する(学習係数を徐々に下げていく)
Nesterov
パラメータθの更新式
- >
サンプルコード
self.v[key] *= self.momentum
self.v[key]-=self.lr * grads[key]
param[key] += self.momentum* self.momentum* self.v[key]
param[key] -= (1+self.momentum) * self.lr * grads[key]
AdaGrad
更新式
サンプルコード
for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * (1/np.sqrt(self.h[key]+1e-7)) * grads[key]
特徴
AdaGradの更新量が0に近づく、パラメータは更新しない
AdaGradは各パラメータの要素ごとに学習率を調整して学習する。各要素の学習率を決めるため変数hとする。勾配の絶対値の大きい要素に更新量を小さくし、勾配の絶対値の小さい要素に更新量を大きくすることで、学習率を調整する。
RMSProp
過去のすべての勾配を均一に加算しない。過去の勾配を徐々に忘れて、新しい勾配情報を大きく反映されるように加算する(指数移動平均)
更新式
サンプルコード
self.h[key] *= self.decay_rate self.h[key] += (1-self.decay_rate)*grads[key]*grads[key] params[key] -= self.lr * (1/np.sqrt(self.h[key]+1e-7)) * grads[key]
特徴
Adam
更新式
サンプルコード
self.m[key] = self.rho1 * self.m[key] + (1-self.rho1)* grads[key] self.v[key] = self.rho2 * self.v[key] + (1-self.rho2)* grads[key]*grads[key] params[key] -= self.lr * m/ (np.sqrt(v) +self.epsilon)
特徴
Jetsonロボット
Jetson nano を用いてロボット作製
YDLiDAR G4
- 本体重さ: 270g
- 最大起動電流: 550mA
- 定格電圧電流:5V450mA
- 検知距離: 16m
- 回転周波数: 5Hz~12Hz
- レンジ周波数:4kHz~9kHz
- 距離精度: <0.5mm(0.10~2.0m)、距離の1%以下(2.0m~16m)
- 角度精度:0.3度(回転周波数7Hz)
ROS SLAM
https://www.slideshare.net/hara-y/ros-nav-rsj-seminar