再帰的ネットワークRNN
RNN
RNNは時系列データ処理に適したNNで、1時刻前のリカレント層の状態を、次の時刻のリカレント層へ伝播する.
特徴:勾配消失や爆発を防ぐため、勾配クリッピングを行う.閾値より大きい時、勾配のノルムを閾値に正規化するため、勾配×(閾値/勾配のノルム)と計算する.
RNNの課題:入力された情報の影響が長期的に及ぶ場合と短期にしか及ばない場合を区別できない (LSTM).<順伝播の式>
# RNNレイヤの実装 class RNN: # 初期化メソッドの定義 def __init__(self, Wx, Wh, b): self.params = [Wx, Wh, b] # パラメータ self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] # 勾配 self.cache = None # 変数の保存用 # 順伝播メソッドの定義 def forward(self, x, h_prev): # パラメータを取得 Wx, Wh, b = self.params # 順伝播を計算:式(5.10) t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b # 重み付き和 h_next = np.tanh(t) # 活性化 # 逆伝播に用いる変数を保存 self.cache = (x, h_prev, h_next) #隠れ層の状態の保存、隠れ層の出力を次時刻の入力に使用するため return h_next # 逆伝播メソッドの定義 def backward(self, dh_next): # 変数を取得 Wx, Wh, b = self.params # パラメータ x, h_prev, h_next = self.cache # データ # 勾配を計算 dt = dh_next * (1 - h_next ** 2) db = np.sum(dt, axis=0) dWh = np.dot(h_prev.T, dt) dh_prev = np.dot(dt, Wh.T) dWx = np.dot(x.T, dt) dx = np.dot(dt, Wx.T) # 結果を格納 self.grads[0][...] = dWx self.grads[1][...] = dWh self.grads[2][...] = db return dx, dh_prev
実装したクラスを確認する.
# インスタンスを作成 layer = RNN(Wx, Wh, b) # 順伝播の計算 h1 = layer.forward(x1, h0) print(h1.shape) # 逆伝播の計算 dx1, dh0 = layer.backward(dh1) print(dx1.shape) print(dh0.shape) for grad in layer.grads: print(grad.shape)
- BPTT(BackPropagation Through Time)で時間展開した上での誤差逆伝播と同じ、一階微分である.
- 全結合NNより、RNNは勾配消失や勾配爆発がおきやすい(系列長が長くなる).
- 勾配消失や勾配爆発の起きやすさは、活性化関数による変わる.
- 勾配爆発を防ぐため、ReLU関数よりも、Sigmoid関数やTanh関数が適している.→勾配消失の回避のため、勾配クリッピング

RNNでのSGDによって最適化を行う.最も単純に全時刻にわたって誤差逆伝搬を行うBPTTという手法がある.
サンプルコード
def bptt(xs, ys, W, U, V): hiddens, outputs = rnn_net(xs, W, U, V) dW = np.zeros_like(W) dU = np.zeros_like(U) dV = np.zeros_like(V) do = _calculate_do(outputs, ys) # batch_size, n_seq = ys.shape[:2] for t in reversed(range(n_seq)): dV += np.dot(do[:,t].T, hiddens[:,t]) / batch_size delta_t = do[:, t].dot(V) for bptt_step in reversed(range(t+1)): dW += np.dot(delta_t.T, xs[:, bptt_step]) / batch_size dU += np.dot(delta_t.T, hiddens[:, bptt_step-1]) / batch_size delta_t = delta_t.dot(U) # RNNでは中間層の出力h_tが過去の中間層出力 h_{t-1}...h_{1}に依存する. # RNNにおいて損失関数をWとUに関して偏微分するとき、それを考慮する必要あり、 dh_{t} / dh_{t-1} = Uである return dW,dU,dV
def rnn_net(xs, W, U, V): batch_size, n_seq = xs.shape[:2] hidden_size = W.shape[0] hiddens = np.zeros((batch_size, n_seq, hidden_size), dtype=xs.dtype) for t in xs.shape[1]: hiddens[:, t] = _activation(x[:, t].dot(W.T) + hiddens[:, t-1].dot(U.T)) #入力xから中間層への重みW、1ステップ前の中間層出力h_{t-1}から中間層h_{t}への重みU、それを合わせた中間層出力 outputs = _activations(hiddens.dot(V.T)) return hiddens, outputs
def clip_grads(grads, max_norm): total_norm = 0 for grad in grads: # Gradsは各パラメータの勾配をまとめたList total_norm += np.sum(grad ** 2) ## total_norm = np.sqrt(total_norm) # 勾配のL2ノルムを取った値をまとめている変数 rate = max_norm / (total_norm + 1e-6) if rate < 1: for grad in grads: grad *= rate
RNN派生モデル<エコーステートネットワーク>
入力の重みUと隠れ層の重みVをランダム値で固定し、出力の重みのみを学習する。勾配消失が発生しにくく、学習が速くなる.<リーキーユニット>
隠れ層に線形結合を導入して移動平均の効果を得る.
双方向 RNN
文章内の文字の穴埋めタスクや過去から現在だけでなく未来から現在までの系列情報を用いることが有効である.
中間層の出力を、未来への順伝播と過去への逆伝播の両方向に伝播する.
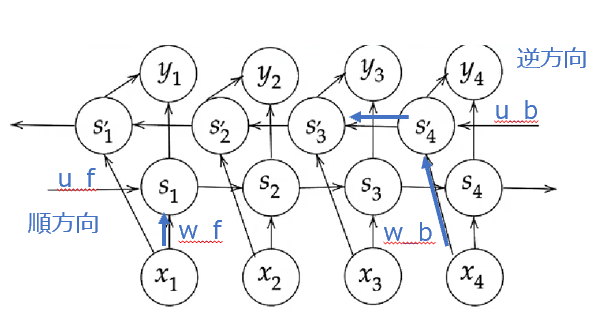
同じ場所に同じものを合体する.一つの特徴が得られる.
def bindirectional_rnn_net(xs, W_f, U_f, W_b, U_b, V): xs_f = np.zeros_like(xs) xs_b = np.zeros_like(xs) for i, x in enumrate(xs): xs_f[i] = x xs_b[i] = x[ : :-1] hs_f = _rnn(xs_f, W_f, U_f) hs_b = _rnn(xs_b, W_b, U_b) hs = [np.concatenatie([h_f], h_b[::-1]], axis=1)] for h_f, h_b in zip(hs_f, hs_b)] ## 順方向と逆方向に伝播した時の中間層表現を合わせたものが特徴量となる ys = hs.dot(V.T) return ys
RNN Encoder-Decoder と Seq2Seq
長期依存性の課題
ゲート付きRNN
LSTM
構成要素:CEC、入力ゲート、出力ゲート、覗き穴結合

入力ゲート
:今回の入力
:今回の重み
:前回の出力
:前回の重み
出力ゲート
:今回の入力
:今回の重み
:前回の出力
:前回の重み
忘却ゲート
:今回の入力
:今回の重み
:前回の出力
:前回の重み
入力と隠れ状態結合状態
セルの値
今回覚えておくべき割合と判断した情報
(tanhは恒等写像に置き換え、バイアス省略)
出力値
CEC:
中間層に記憶をため込む(記憶機能のみ).学習機能がない.
入力ゲート:CECの覚え方を身に付ける学習
出力ゲート:どんな感じでCECの情報を使うを学習
しかし、ずっと過去の情報が削除できないため、忘却ゲートを入れる
さらに、CEC自身の値は、ゲート制御に影響を与えないため、覗き穴結合を入れる.
記憶セルの状態を結合させる.
サンプルコード
def lstm(x, h_prev, c_prev, W_in, W, b): n, m = h_prev.shape A= np.dot(x, Wx) + np.dot(h_prev,Wn) +b #全部の行と変数mの値分の列を指定 f=A[ : , : m] g=A[ : , m: 2*m] i=A[ : , 2*m: 3*m] o=A[ : , 3*m: ] f = sigmoid(f) # forgetゲート g = np.tanh(g) # 新しい記憶ゲート i = sigmoid(i) #inputゲート o = sigmoid(o) # outputゲート c = f * c_prev+ g * i #次の時刻の記憶セル h = o * np.tanh(c) #次の時刻の隠れ層におけるoutput return h, c
GRU
Gated Recurrent Unit
LSTMはゲートが3つで計算負荷が高い課題がある.
パラメータを大幅に削減し、精度はLSTMと同等.
記憶ゲートがなく、リセットゲートと更新ゲートがある.

GRU (Gated Recurrent Unit) | CVMLエキスパートガイド
リセットゲート
更新ゲート
次、仮の隠れ状態
出力値
前回:
今回:
サンプルコード
def gru(x, h_prev, W_in, W): n,m = W_in.shape W_in_z, W_in_r, W_in = W_in[:, :n], W_in[:, :n],W_in[:, 2*n:] W_z, W_r, W = W[:, :n], W[:, n:2*n], W[:, 2*n:] z = _sigmoid(np.dot(x, W_in_z) + np.dot(h_prev, W_z)) # updataゲートの出力値 r = _sigmoid(np.dot(x, W_in_r) + np.dot(h_prev, W_r)) # resetゲートの出力値 h_hat = np.tanh(np.dot(x, W_in) + np.dot(r*h_prev, W)) #過去の隠れ状態とリセットゲートの出力のアダマール積 r * h_prev h= (1-z) * h_prev + z * h_hat #更新ゲートの出力を混合比とする過去の隠れ状態と仮の隠れ状態の混合が入る # or h_next = z*h_pre + (1-z) * h_hat return h
長期依存性の最適化
Attention
- Soft attention :
softmax関数で確率分布を求めてその確率分布を用いて重みつき平均を求める方法である.
- Hard attention:
softmax関数で確率分布を求めてその確率分布に従って抽出された1点だけを得る方法である.
1.Source target attention: keyとValueがエンコーダ側の情報、Queryがデコーダ側の情報で分ける。2つの系列間の対応関係をとらえる.
2. Self attention:同じ情報源から計算するもの、同じ文章内の単語間の関係をとらえる.
3. Global attention:Attentionを使わない系列変換モデルでは長系列データ学習は難しい、エンコーダの初期に入力された情報がデコーダまで伝わりづらい
「デコーダの対象時刻の隠れ層の出力」と「エンコーダの各時刻の隠れ層の出力」から重みベクトルを算出して、
その重みベクトルと掛け算して、Ctが得られる.<コード>
デコーダの隠れ状態のサイズ Nx H
h.reshape(N,1,H).repeat(T, axis=1)
アテンションの重みは N X Nとなる.
H方向に合計np.sum(t, axis=2)